
This is part 2 of a series of articles aimed at demystifying the concepts of Generative AI for Business Leaders who are stuck between FOMO (Fear of Missing Out) and FONU (Fear of Not Understanding) when it comes to betting big on Generative AI. I highly recommend that you start the series from Part 1 to get best out of this article.
Many of you would have come across jargon like Pre-training, Finetuning, RAG etc. during the first stage of deciding your organization’s Generative AI strategy. However, if you do not understand the basic ideas behind these, your initial foray into Generative AI can go horribly wrong, leading to a feeling of fear (I can’t do this) or defiance (I don’t need this). Therefore, in this article, we will explore these ideas through simple examples and analogies.
Disclaimer: If you are looking for the underlying mathematics and technology details behind Generative AI, this series is not for you. Also, I may oversimplify certain concepts for ease of understanding.
What is Training? How is it different from Fine Tuning?
As we saw in the last article, a Generative AI Model (like LLM for text based outputs) learns like a child by looking at existing information (like “Alice in…” is generally followed by the word “wonderland”) and then using this understanding to answer subsequent questions. This process of learning when enormous amount of data is shown to a Model to get it ready to answer questions or perform tasks in a seemingly intelligent manner, is called Training. It is similar to the process of schooling that prepares our children to solve real world problems as adults.
However, at times our children may need specialized knowledge to become better at solving a specific type of problems. For example, college education may tune them to solve Engineering problems through a B.Tech. course or solve Biological problems through a Medical course. This is equivalent to the process of Fine Tuning for Generative AI models. For example, a Pharmaceutical Company may want a LLM to respond through scientific terms rather than general terms (like the word “trial” should automatically be understood a clinical trial and not a legal trial). Here the company may decide to run specialized training for the LLM on a huge amount of pharmaceutical data (may include proprietary data not available in the public domain). It is like sending a LLM to a college to specialize in pharmaceuticals.
In a nutshell, Training and Finetuning for Generative AI models, are respectively equivalent to School and College Education for a child.
When to Train and When to Finetune?
Once the ideas of Training and Finetuning are understood, the obvious question becomes “Why Train at all if Models trained on large corpus of data are already available? Why not just Finetune and be done with it?”. This is a fair question, the answer to which lies in your requirement from the Model.
Imagine you are someone born and brought up in India, and have completed your school education with a standard curriculum acceptable everywhere. However, it is the year 4025 AD and intelligent civilizations have been discovered on other planets. Now imagine you travelled to one such planet where the language, culture, way of life, environment and even the laws of physics were different from what you were educated in on Earth. Now, you will need to re-educate yourself in accordance to your new home planet, from the most basic level.
This is what training your own model looks like. It is needed only when your business or usecase for the Model is so unique that any of the pre-trained Models are not close to what you need your model to know. This is an extremely rare situation.
However, I have often observed business leaders jump right to training their own models claiming that their business model or way of doing business is extremely unique. This approach invariably fails and gives way to finetuning after initial dissatisfaction for the following reasons. Firstly, it is highly unlikely to find a usecase that is truly unique and has no precedent in the training data of a commercial grade LLM, and secondly, training your own LLM such that it is effective, requires several peta-bytes of data and costs several million dollars which is generally not available with a single enterprise. The exceptions to this rule could be defense related projects or state sponsored LLMs that need excusive cultural focus.
The next question arises “Should all businesses be finetuning the GenAI Models?”. The answer again lies in the requirement from the Model. The decision of Finetuning is like choosing which stream to pursue for college. Going for one stream (like Medical) will lock your options to go for a career in other streams (like becoming a lawyer). The process of switching streams is both time-consuming and costly as it entails going back to college to get the relevant training in the new target stream.
Likewise, Finetuning is a time-consuming and costly process as the pre-trained model needs to be trained & tested on a large corpus of data specific to the target field (e.g. pharmaceuticals). This should be done when there is requirement for extreme focus on the target field, in all interactions with the Model, and the language of the field is very specific to it. Typically these usecases have very high mission criticality with little to no scope of making mistakes. A few examples of such fields are Medical, Legal and Financial. Also, once a model is finetuned in a field (like Medical) it doesn’t remain very reliable for other fields (like Legal).

What is RAG and where does it fit into all of this?
RAG is short for Retrieval Augmented Generation. Again, do not be daunted by the terminology. It can be understood in a very simple manner.
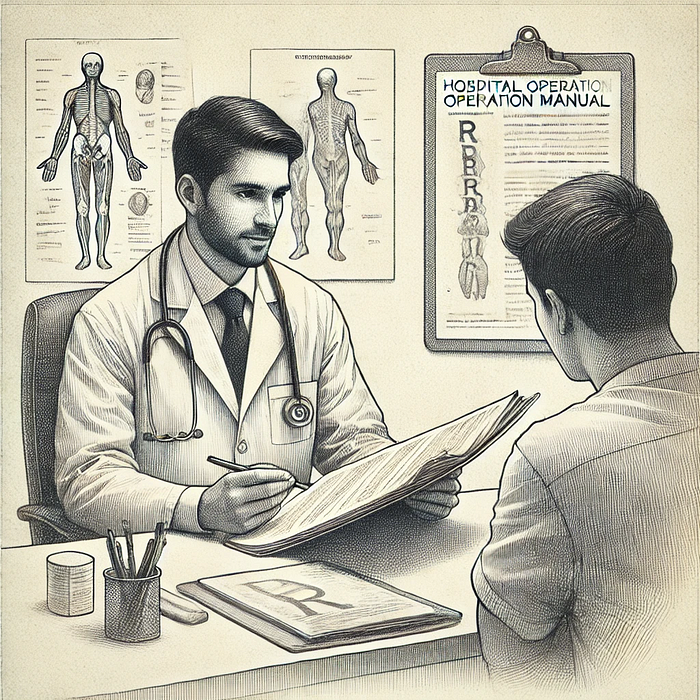
Imagine that a child is college educated and has become a Doctor. He then goes to work at a hospital (like Apollo Hospital). While the medical science he is trained during college is applicable as it is, he will need to learn about the specific procedures, protocols and terminologies prevalent in that hospital. For this knowledge, he refers to the hospital operation manual that is specific to that hospital. The manual is regularly updated and he refers to the latest version every time he needs information on hospital specific practices.
In other words, he Augments his medical knowledge (learned in college) with information that he Retrieves from the Hospital specific Operation Manual to perform his duties as a doctor at that hospital. This is equivalent to Retrieval Augmented Generation (RAG) for a Generative AI Model.
When using Generative AI in your enterprise, you may want it to refer to the data that is specific to your organization, and that changes dynamically (like HR Policies, Financial Information etc.). Here the LLM (equivalent of the college educated doctor) is supported by organization specific database (equivalent of the hospital specific operation manual) to generate responses that include the organization specific knowledge. The LLM refers to the data dynamically (like the doctor refers to the manual while performing his duties), and therefore no finetuning is required. This saves cost and allows the data to be updated as often as needed, without affecting the LLM.
Conclusion
Training, Finetuning and RAG are all aimed at providing different levels of specialization to the Generative AI models. Training is the most broad and costly, whereas RAG is most narrow (specific) and cost effective, with Finetuning somewhere between the two. The decision of when to use what depends on the motive of the Generative AI model. As a business leader, you need to ensure that the right tool is being used for the right objective.
Remember, using an axe where a scalpel is needed will invariably kill the patient.
Now that we have our Generative AI model ready for use, next come questions like “What it can and cannot do?”, “What is the difference between Analytical and Reasoning Models?”, “What role does my enterprise data play in deriving benefit from my GenAI model?”. These are some of the questions I will be addressing in my next article.
Request
Your feedback is a gift. As I put in multiple manhours to write these articles (and I promise that this is not generated or edited using GenAI 😄), I would highly appreciate if you could share your feedback and help me improve.






Leave a comment